


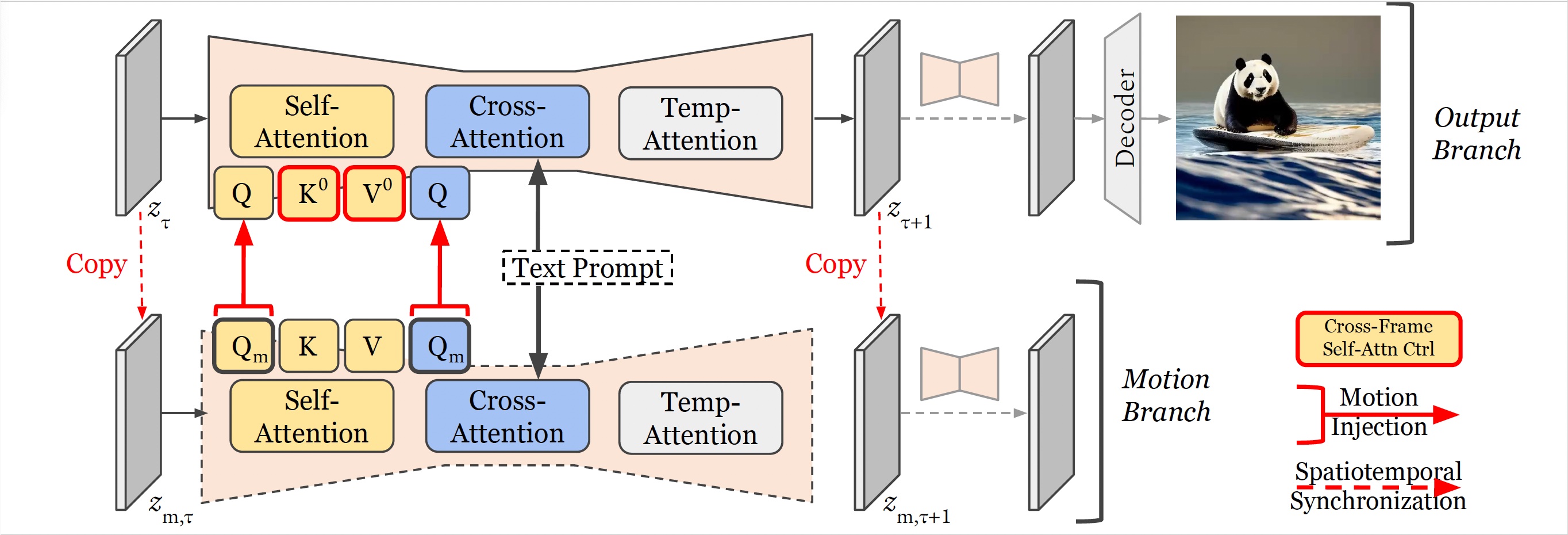
We introduce UniCtrl, a novel, universally applicable plug and play method designed to improve the semantic consistency and motion quality of videos generated by text-to-video models without necessitating additional training. Our work makes the following contributions: We ensure semantic consistency across different frames through cross-frame self-attention control; We also enhance the motion quality and spatiotemporal consistency through motion injection and iterative initialization. Our experimental results demonstrate UniCtrl's efficacy in enhancing various text-to-video models, confirming its effectiveness and universality.




In our framework, we use key and value from the first frame as represented by K0 and V0 in the self-attention block. We also use another branch to keep the motion query Qm for motion control. At the beginning of every sampling step, we let the motion latent equal to the sampling latent, to avoid spatial-temporal inconsistency.








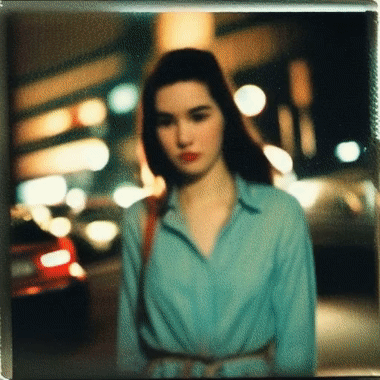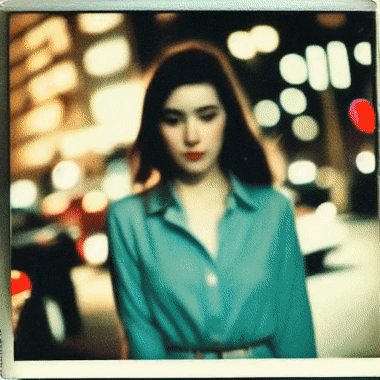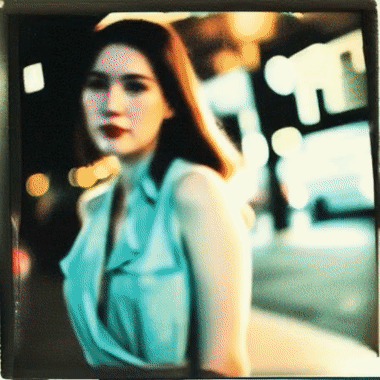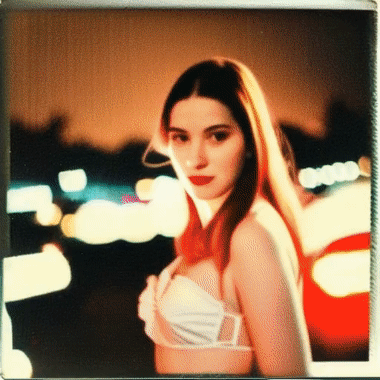



We show case UniCtrl's adaptability to varied text prompts, leveraging UniCtrl to significantly improve temporal consistency and preserve motion diversity. Additionally, we demonstrate UniCtrl's seamless integration with FreeInit.





Each row displays a sequenceof video frames generated from the identical prompt: A panda standing on a surfboard in the ocean under moonlight. The section labeled K and V mismatch illustrates the frames produced when there is a discrepancy between key and value pairs.Conversely, the section titled K and V match showcases frames generated when key and value pairs are inalignment.

@misc{chen2024unictrl,
title={UniCtrl: Improving the Spatiotemporal Consistency of Text-to-Video Diffusion Models via Training-Free Unified Attention Control},
author={Xuweiyi Chen and Tian Xia and Sihan Xu},
year={2024},
eprint={2403.02332},
archivePrefix={arXiv},
primaryClass={cs.CV}
}